
Some cases of data recovery or data loss in the last somewhat over ten years I find worth mentioning.
After describing my approach in the first part, I would like to describe here some characteristics and failures that led to this setup – more or less as anecdotal evidence and deception at the same time. Depending on the case, I would at least at least claim to have always learned something (also about the non-determinism of IT) and still see myself confirmed in my assumptions.
Only rarely I did actually lose data. Each time it was a matter of Recovery Point Objective (RPO) and therefore a more or less conscious decision, or trade-off.
I hope I’ve laid out all the memories correctly, but some of it was a long time ago and the details weren’t that important until now. Not everything always falls exactly into the Backup & Recovery category, but the other issues probably fit into this article and are for entertaining purposes.
| Disclaimer: I do not get any money to promote or bash any software. I only share my opinion and experience. The weakness of some tools could be just my own inability to use them properly – so please do not use this as a general criticism of any of them. |
Unlucky timing (aka the hardware is to blame)
In June 2011 my laptop stopped working a few days before the relocation (a quarter of a year later I was able to fix it, it was probably a loose connection on the mainboard). My complete move planning was already in OneNote back then, but still without cloud only local. My current server was still my gaming PC at the time and could then just take over the work. This was at that time fortunately not yet in the 35-kg case and thus somewhat more mobile than today.
I had access to the backup disk, but could also continue working directly on the HDD from the laptop (just in the other PC). The OneNote notebook was easy to import after installation – done.
For ordering replacement IT, the relocation was of course impractical as I only wanted to make one trip and the delivery location depended on the delivery date.
On another side note, it was also unfortunate that the municipal structure was adjusted a few months before the relocation. This changed the postal code, but it passed me by and was usually not a problem since experience shows that the old postal code still works for a very long time. But then the payment of the order failed because the bank changed my zip code internally for verification of the credit card payment and did not inform me. I only knew the old one and didn’t even get that idea. Anyway, due to the incorrect entry of the zip code, my credit card was blocked quickly and this delayed the delivery.
And the moral of the story: Technically speaking, I didn’t need a backup in this case, because only the device was defective, but not the drive. My concept with available additional IT equipment worked this time. Having important data available in the cloud on multiple devices only came up later.
False destination (aka the tool is to blame)
In August 2012 I was photographing a lot in the Eifel on a Saturday: Mainly in and around Eltz Castle and my apartment in Cochem Sehl from the other side of the Mosel. Since I started taking photos only a few months before, my storage processes were not very mature yet. After that I put the photos on my laptop, but then didn’t back them up and went on a two-week training course on Sundays. There my laptop crashed (I don’t remember the details) and I wanted to use Windows 7 recovery. To do this, if I remember correctly, I used the Dell tool that came with the computer. Unfortunately, this was not optimized for my drive setup (in 2012 SSD + HDD was still rare). The tool installed the repaired Windows on the HDD instead of my SSD and thanks to the previous encryption, little was then recoverable (especially while traveling). After the next incident, I know better. I have my mobile HDD extra not taken, because the scenarios where then both disks are gone, seemed more likely than that I need the backup or have to update. I have unfortunately only two remaining photos of the castle Eltz, because I edited on the course and uploaded directly to Google Photos. Since I relocated from the Mosel two weeks later and haven’t been back since, I haven’t been able to reshoot the photos yet either. The later described restoring of the photos on the SD card did not occur to me, because I was busy enough with the new relocation directly afterwards. Besides, I also experimented a lot with the camera on the training course, so I suspect my only SD card was full to the edge at the time anyway.
What did I learn on it? Special backup and restore tools sometimes break more than they help. Important data should be backed up multiple times (on demand) before traveling (RPO), and if IT fails while traveling, having a backup with you at all times would be helpful – but only if it is not the only one. On the other hand, I still like to take my backup HDD with me on trips when my laptop stays at home.
Too much virtual memory (aka the missing warning is to blame)
I was going to write a separate article about the next case, but it fits in here as well. About the details I’m not so sure anymore, but I hope it’s coherent.
I don’t remember exactly when it was, but it could have been early 2014. The core of the problem is the use of Storage Spaces, which I already hinted at in the articles SATAnical flames in the PC and in the first part.
At that time I had a Storage Pool consisting of several HDD (500 GB to 3 TB) with a total size just over 12 TB. On the storage pool I had few storage spaces, all encrypted with Bitlocker. I wanted to merge these into one large Storage Space for convenience. So I used PowerShell to increase the largest Storage Pool to 50 TB – significantly more than the pool actually had in storage space. So far it was no problem. Even the encryption didn’t break my plans here. I directly emptied the other Storage Spaces and moved everything to my super-duper 50 TB Storage Space and removed the other empty Spaces. All that copying took a while, so I gave my server its well-deserved break afterwards and shut it down.
The next time I booted up, however, Bitlocker said that the integrity of the drive was broken. As a research showed, Bitlocker doesn’t like drive size increases at all – but there was no hint when increasing the size. Thus, access to the data was no longer possible. I read a lot for a few days, experimented around and found a workaround:
With the Windows system tool repair-bde I could rescue data from the space to a new drive. Here the Bitlocker recovery key is one of the parameters, besides source and destination. Unfortunately I didn’t have a 50 TB HDD at hand. But if I take a smaller drive, the recovered file system is RAW only. With chkdsk I could find and fix file system errors, but the file system remained RAW (here it could have been something else). However, with a tool for recovering files from a corrupt NTFS file system, I was able to view some files and access them without problems.
I was so convinced of this approach that I bought four hard disks of 4 TB each (that was a serious amount of money at the time). If I remember correctly, I had to buy my PCI-SATA controller as well, because of course I didn’t have four SATA ports free. From these I built a new storage pool. Since there was no room in the case for the four additional HDD, it looked pretty wild. Then I used repair-bde and chkdsk to create a storage space with the faulty RAW file system. Now I had to get brave and deleted the original defective storage space (another 4 x 4 TB was not possible). Then I used the NTFS tool to restore the files to a new Storage Space in the old Storage Pool.
Now I could distribute the files from this one (now no longer super-duper) Storage Space to many different Storage Spaces on the new Storage Pool on the four 4TB HDD – of course again with Bitlocker. I mean for the intermediate steps I did without parity in the Storage Spaces (and used mirroring?) to make it faster. I did not use Bitlocker at all in the meantime. Nevertheless, these steps took more than a month together. This is certainly due to the old hardware (at that time only 6 years old), but mainly due to the terrible performance of Windows Storage Spaces. The fact that the computer also ran at night would really worry me today – after my small fire in the server.
Maybe it would have been easier and faster with other tools or just other parameters of repair-bde or chkdsk, but I didn’t want to experiment more than necessary, because that’s how the evil came up in the first place.
I have tried to illustrate the whole thing with a graphic:
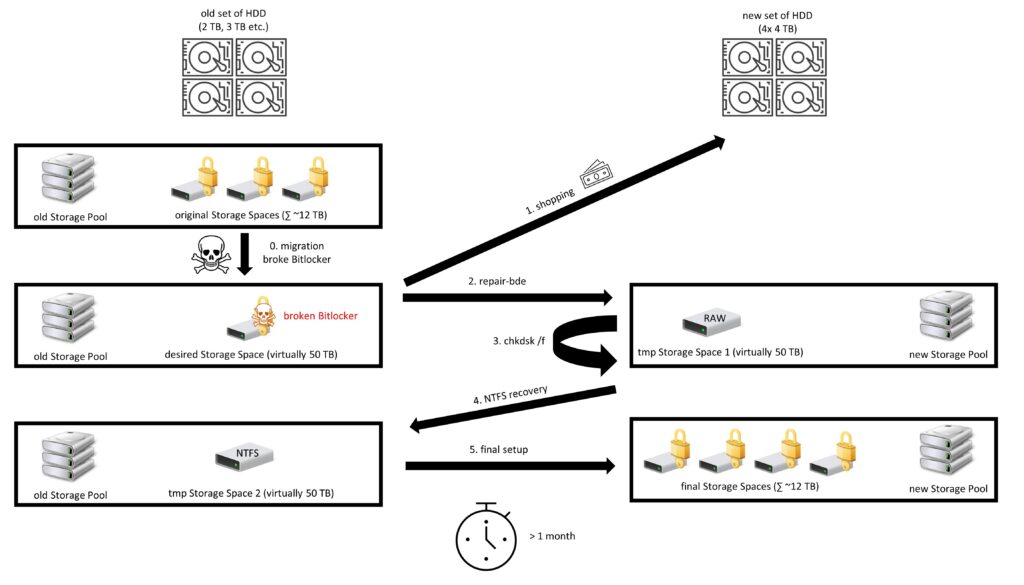
However, the result also has advantages for me: Since then, I have the old HDD left over, which I still partially use today for the purpose of off-site data backup. The basic structure of the Storage Pool and Spaces has remained the same until today.
Because it fits so well, I have some more details about my storage pool: According to Microsoft, a pool with exactly eight drives of the same size is the most performant. I meet that number, but the storage structure is still more or less JBOD. Only one of the HDDs in the pool is still one of those purchased for recovery.
In the end, I wouldn’t know that a single file was missing or not recovered. I still find that pretty awesome to this day.
I was able to learn a few lessons from this incident:
- Encryption is not a toy: every time I have edited (Bitlocker) encrypted drives since then, I have updated backups, decrypted Bitlocker, edited the drive and re-encrypted. This was especially necessary when adjusting the over provisioning of SSD. I no longer resized Storage Spaces, but recreated them and migrated the contents. Also, firmware updates of Bitlocker-protected drives are now only available after decryption. Nevertheless, Bitlocker has proven to be reliable, because the Bitlocker command line tools are powerful, reliable and part of Windows (and work even if the Bitlocker GUI has been locked by the admin :-).
- Storage Pools and Storage Spaces are not toys: almost all Storage Spaces since then have an off-site backup. The Storage Spaces are so small (max. 10TB) that a restore is easier. Furthermore I see possible problem cases especially when changing disks of a Storage Pool.
- Reboot does well: Important changes to the system experience a reboot for me. Then only one Storage Space would have been defective, but the others would not have been moved and deleted yet. On the other hand this created the pain to find a solution.
- Patience is a virtue: Finding and trying the solution took a few days. Here I read a lot and prioritized the solution option by irreversibility. Especially before deleting the edited storage pools, I did a lot of testing, reading and pondering for a while and not making the data loss permanent. That may not always be my strong skill, but it worked well here.
Mainboard malfunction (aka it’s again the hardware to blame)
Here is a short anecdote about another hardware failure. In spring 2015, I was on a training course in Cologne when my mobile workstation suddenly went out. I had a loose connector and without a laptop it wasn’t easy to take notes and learn, so I spent a lot of time analyzing it despite the course (I think it was M_o_R and thus not bad).
It turned out that my laptop was probably packed too tightly on the way to Cologne and as Dell confirmed to me later the mainboard was cracked at the power supply. The three-year warranty was already over and Dell estimated a four-digit amount for the repair. Without the battery, however, the mobile workstation works smoothly and is not sensitive to shaking – just less mobile. Since the 2011 device had only undergone some upgrades at the beginning of 2015 (new SSD + more RAM), its lifespan was not yet over and I could continue to use it myself until 2018. In the family, the device still runs without problems until today even without battery and runs (hopefully until the EoL of Win10). Not even Forrest Gump has run for eleven years.
Power supply in general seems to become a problem with my devices: On the successor, the battery blew up and caused the touchpad to do ghost movements. On my wife’s laptop, the battery has blown up and pushed the case open. Both devices have been running without a battery for years, although my touchpad no longer works without counterpressure from the battery pack. The battery of my father’s 2in1 device even crushed the glass keyboard of the device and caused a total damage.
In terms of data availability, I was able to determine something: I didn’t have any spare IT with me on the course and would probably have had to buy a completely new device to be able to work. The HDD would have been usable without any problems.
Tight is right (aka the cheap is to blame)
A very typical case of supposed data loss occurred right on the honeymoon. In the meantime, the volume of data increased due to photography and I shot up a few SD cards during the week. Usually I bought SD cards from SanDisk, but there were also three SD cards from Trancend. I didn’t notice any difference when shooting, but within a few years all three Trancend cards broke – but none from SanDisk. Anyway, one of the cards broke right on the honeymoon and it took a few data recovery tools after that to recover most of the photos. With the damaged pictures, mostly only the RAW or the JPEG file was affected, so the total loss was limited.
Learned something about diversification in IT: Had I relied only on Trancend, I might have had more failures and considered it normal for cards to fail. If I had only SanDisk, I would have no distrust of the cards without failures and less backup (swap cards even if they are not full, etc.). Through the mix, the differences in card manufacturers have been very evident.
I don’t have the business case for a camera with two card slots (nor do I have the business case for the other features of these cameras). I haven’t had to buy new cards in years, but if I did then SanDisk and only from reputable dealers.
The day that never existed (aka higher powers are to blame)
I had a separate blog article on my list about this one as well, and I can save it now.
In January 2017, I shot some photos with my robot that I was given for Christmas. The process was as usual and quite successful: shoot photos, move them from the SD card to the mobile workstation (to the SSD), edit them there and then copy the final photos to my documents (on the built-in HDD). Some pictures I immediately uploaded to Google Photos and created an album. This was my rescue, but I didn’t know that yet. I haven’t moved the edited folder with the RAW files to my server yet, though. I rarely do that immediately after editing because the server is usually powered off.
At the end of the day I turned off my laptop and when I turned it on the next day the strangeness started. I found another file not with editing from the previous day and then searched for the photos. They were neither on the SSD nor on the HDD. To make a long story short: All files and also the event history of Windows were as if I had not even turned on the mobile workstation the day before. Even with various data recovery tools I did not find anything on the SSD and HDD that would point to the previous day. A search on the internet was unsuccessful (I’m sure there’s a magical word). It was not a big photo shoot after which I always double backup the data today. If I had turned on the server the day before, I would be interested to know if the data on the server or on the external HDD would not be persisted either.
It remains a mystery to me. In my first job out of university, we had a piece of software that supposedly did just that (had never tested it properly). This was for a teaching classroom, to reset the PCs there to the origin on a daily basis. I don’t know if Windows comes with that out of the box and just had a flag for it set incorrectly at boot. At least that’s what I tell myself it must have been.
Fortunately, there was the album in Google Photos. At least that helped me not to declare myself crazy (so not even more than usual anyway). If my laptop had also reset the Google cloud, you would have read about it earlier. Then I completely restored the RAW files from the SD card and just developed the photos as they were in Google Album (but I could have saved myself the effort).
Again, something to learn and improve: SD cards also serve as backups for a while (until they were overwritten). Until today I check after a boot of the system if the last edited files are really changed. There have never been any problems again. Since then, I update the backup on the external HDD on an event-driven basis – although I don’t know if it would have helped here. I think I had this lesson above, but RPO is always in need of improvement, I guess. Since data wasn’t really lost, the pain wasn’t great enough for fundamental changes.
Remove the backup at the same time (aka again the tool is to blame)
I don’t know exactly when and why, because it only became apparent much later – way too late. I guess in 2018 something went wrong with an open heart operation from the storage space for the RAW photo archive. Usually a rebuild of the storage space is done very quickly in an automated way and then a check of the file system for errors helps. That seems to have slipped through my fingers here. That doesn’t have to be the cause either, but I think it’s likely.
I found out really late that some folders were corrupted and several photos were missing. In the meantime I updated both external copies and thus deleted the photos there as well. In Synkron this is not displayed as clearly as for example in Beyond Compare and therefore I did not become aware of the deleted photos. I was able to recover most of it with chkdsk – but not all of it.
What I learned: As described in part 1, I switched from Synkron to Beyond Compare only when I was recapping the issue – years after I discovered the loss. I guess that’s when I get stuck in my established processes too often – and that’s generally dangerous in IT, but all too human. Now, in Beyond Compare, the analysis is sensibly displayed before copying, and you can immediately see which data should be deleted in the target – which should never occur with photos in the archive. And I now do chkdsk a bit more regularly even without a concrete suspected error in NTFS.
No boredom under this connection (aka the storage pool is to blame, but so is the hardware)
Again, I’m not sure when it was, but mid-2019 fits roughly. I already knew that one of my two USB-A 3.0 ports on the laptop would sometimes have drop outs, but at the time I hadn’t explored the details. Since my server doesn’t have USB 3.0, but does have fast Ethernet, I connected my wife’s backup HDD to my laptop to push a copy to the server (Ethernet instead of WLAN).
At the time, I had also added a Storage Pool to my wife’s external HDD so that I could use the Storage Spaces as flexible partitions for different purposes. In this setup, all Storage Spaces are as large as the entire drive itself and can be used with maximum flexibility, with very low overhead. Then there are no problems with Bitlocker when adjusting the partition sizes (a lesson learned above).
In this case it was fatal. Due to a dropout of the USB port and a short disconnect, combined with the immediate restart of the HDD, the storage pool had probably destroyed itself. Unfortunately I didn’t save a screenshot or the exact error message, but all my research on the internet resulted in the fact that the Storage Pool with all its Spaces is irrecoverably (under normal circumstances) lost. Well, it was only the backup and a part was additionally on the server, so I formatted the HDD and rebuilt it without the Storage Pool and updated the backup. With me a comparable procedure would have taken forever because of the amount of data. The relatively few files in this case make the process quick and easy. Now there are no more different drives there, but there is one more tier of folders.
Meanwhile I know that these connection dropouts of the one specific USB port only occur with USB 3.0 or mass storage devices. Other USB devices (mostly I use my headset) never cause problems. And after the next experience I know from that it is neither a software problem nor the motherboard, but the physical USB port on the laptop.
And the moral of the story: storage pools are not always useful and definitely an additional source of errors. Especially when it comes to other people’s storage devices (even if it’s strictly speaking mine), I prefer to keep my hands off. If you know about defective USB ports, you should not use them either. I don’t use it for storage media anymore. If I need more than one, I use the USB-C hub on the third USB 3 port. However, I still use the setup of multiple Storage Spaces as flexible partitions for me. It is also a great practical benefit for me in combination with Bitlocker, which I would otherwise have to realize with multiple storage devices.
No access on this controller (aka the update is to blame)
On Christmas Eve 2019 I wanted to update the drivers of my laptop in the morning (of course with gingerbread and Christmas tunes). The goal was to patch away the problem described above with the one USB port. Unfortunately I had no access to the system after that. I also didn’t have much time for an analysis and so that I would have my laptop for Christmas, I immediately went to the only Saturn in Munich that had an m2 SSD case in stock and got out with it 10 minutes before closing time. Unfortunately, contrary to the “advice” of the staff, this adapter does not have the ability to access NVME. With that, I was out and could not figure out the cause. With the trip after Christmas to my parents – two hours away from any electronics store – I couldn’t continue to work on the problem either. For the meantime, I ordered another NVME SSD and an external NVME enclosure from the Internet, but they also arrived much later than specified. In the meantime, the new year had been and I was also back home.
The tests showed: all SSDs run without problems and my laptop simply does not recognize SSDs in both m2 slots anymore. I even knew the Bitlocker recovery key by heart in the end during the many attempts. Now I only had the opportunity to contact the manufacturer Schenker and send in the device after a phone call with support. Here I only sent along the empty new SSD and no SSD and HDD that were previously used in the system. Less because I wanted to prevent unauthorized access, but primarily to prevent the disks from coming back later with less data (see above when the tool was at fault). It was actually the NVME controller on the motherboard that was defective and the motherboard was completely replaced. After installing the old drives into my laptop, the new TPM on the new board was a bit tricky, but finally it worked as expected. Unfortunately, it took a good three weeks in total. Interestingly, the USB port that I wanted to update all the drivers for in the first place is still broken, so now I know it wasn’t the mainboard.
In the meantime, however, I was able to work directly on my server with the backup of the data right before the defect on the external HDD. But since it wasn’t such a nice working on the PC and I didn’t want to actively work on the backup so much, I had time for Netflix (The Witcher and Lost in Space just came out) and to do puzzles (it had only been Christmas).
It was annoying, but my approach worked anyway. And since then I have a second SSD in the system and that is also very practical. Also the external NVME enclosure gives me some security when accessing it without another system with m2 port in the house.
And the moral of this story: patches and updates are good, but all system-related patches go hand in hand with a data backup and for some I prefer to sit out the problem, especially if I don’t see any attack potential mitigated by the patch.
Otherwise, a common thread throughout this article is the experience that HDD/SSD work fine in other devices – if you have suitable adapters. I have more of those now. I usually have the important data available with it.
That was not so obvious as expected (aka China is to blame)
At the beginning of 2022, I received a USB stick from a family member that seemed to stop working. At first I was skeptical and the cause was obvious to me at first glance. It must simply be a fake device: I immediately thought of one of these obvious fakes, where a controller specifies more size than is present and can also write this data. But when reading it, it can’t conjure up all the data. That’s what I believed until I found out that 128GB USB flash drives really are that cheap today.
But since none of my PCs and other devices (also tried OTG to Chrome OS and Android) like this stick, I guess it’s just broken. It’s not just the file system as formatting doesn’t work anymore either. Disk management also behaves non-deterministically with this USB stick.
I learned that large USB sticks are no longer expensive, but also not always good.
The other peoples’ data (aka finally someone else is really to blame)
In the summer of 2022, an friend asked me to take a look at her external hard drive, because it is no longer recognized on the PC. This was also the case with me, but with suitable tools something was possible. After some trial and error, I made a 1:1 copy to one of my HDD. The whole thing took about 20 hours for ~100GB (the HDD was 250GB). According to CrystalDiskInfo there were about 24,000 UltraDMA CRC errors after copying. When a SATA cable (this time the data cable, not the power cable again) blew up in my face, I once had 30 of them. Therefore I assume that this HDD has really reached the end of its life.
After repairing the file system, there was a lot of data. After some magic from chkdsk on a clone of the recovered partition, some additional files were also found – but not many. Whether it was all the original files on the disk I don’t know, but according to feedback nothing was missing.
And the moral of the story: Helping others doesn’t hurt. So I was practicing a scenario again and just invested some time and power.
SATAn takes the data personally (aka the hardware is always to blame)
I went into detail about the small quick fire in my server in the article SATAnical flames in the PC.
Here, I’ll just touch on the lessons learned and consequences for my backup: First, it was good for me to see that even small cables can have a big effect. With the new server, I’ll try to have SATA power cabling that will prevent me from losing four drives at once in the event of a cable failure (I’ll be helpless when it comes to the power supply). I doubt I’ll succeed, because an initial search led to the result that actually all power supplies have multiple SATA power connectors in series or parallel. So I can only hope that the quality of the included SATA cables is high enough.
If it had come to a failure of the four drives, the entire storage pool with all Spaces would probably be lost. So much redundancy that any four HDDs could fail is expensive to me. I don’t know of any data recovery tool that would have helped here. After all, some data was stored (with a lousy RPO) on external HDD and even in another household. So even in the extreme case that the entire house burns down, I would still have some data (which would probably be the least of my worries). The 3-2-1-0 principle (which was the origin of the first article inspired by a Heise article ) would have been applied here.
Moving is good – checking is better (aka who’s to blame again now?)
Just before finishing this post, after the switch from Synkron to Beyond Compare announced in the previous article, I was shown an error. This was noticed when copying data from the server to the backup HDD. Two directories in my RAW photo archive supposedly no longer exist, but these are now empty files. Also, some files are now only 0 kB in size. This saves disk space, but is useless. Since it is only the offloaded files, the damage is limited, but fortunately I have enough motivation to make some experiments.
The first problem is that PhotoRec and TestDisk have completely different drive names than I get with Windows native and various tools. Windows doesn’t like sdj, sdk, sdx etc..
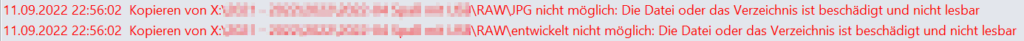


The GUI version of PhotoRec has more meaningful drive names. There the UUIDs are displayed as in the PowerShell under Get-Disk. But also only these and in other order, so that a transfer to the CLI version is not possible. In the long run, it is advisable to configure all Storage Spaces with different sizes, so that they can always be distinguished.
Unfortunately, only senseless and gigantic large files (>60GB) are found, which make the SSD full and therefore ensure that the program does not run. Since there was not a single meaningful file, I abandoned the attempt for now.
Recuvia as an alternative crashes directly on startup ☹.
GetDataBack also only restored files with 0 byte size, but at least also from the directories that are now files. But also many files that are not gone at all – that is alarming.
Up to the editorial deadline no files have been restored so far. Currently running chkdsk and in the quiver I still have Windows File Recovery from Microsoft and then I see further.
[Update 2022-09-29]: After a 26-hour run of chkdsk, the folders and files were back, but all files were only 0 kB in size.
I am wondering if the files were not written correctly in the first place directly when they were moved. Then any recovery attempt would be wasted. Since the source was an SSD, a recovery attempt there is virtually pointless as well. Hard to say, so I try around a bit.
And also this experience has some lessons for me now: If it would have been really important data, I would not have moved it to the server and backed it up from there. Instead, I would have copied them and moved the original directly to the backup (without going through the server). But luckily I don’t really have any important data only on the server – but annoying is still every data loss (apart from the entertainment factor here). In the end, this could also be classified as an RPO decision.
It would also be interesting to know if a check immediately after the move would have already revealed the error, and if a repair would then be more successful. We will never know. If so, I know where I will write something about it.
Summary
As it turns out, some lessons have been learned several times now: the RPO has been improved. However, improving the RPO in particular always means extra work (plugging in the HDD, booting the server, etc.) and is therefore a cost-benefit calculation. To be more strict here is also difficult. At least for important data I do that, but I have never calculated a concrete marginal benefit or explicitly classified my data according to availability requirements. Implicitly, I’ve been doing it for years.
It is not always possible to guarantee having the required replacement IT with me when traveling to be quickly ready to work again (RTO). Here, editing data in the cloud (or with Resilio Sync) on the smartphone would be a real option. In that case, however, I weighed confidentiality, availability, and effort and arrived at what I hope is a balanced solution of only having some data with me.
Aggregating the scenarios above, I realize that the following is dangerous for my data:
- the time just before a move
- the Christmas season
- storage pools and storage spaces
- when I am allowed to touch IT
In summary, it can be said that a data backup always has problems and complexity often harms more than it helps. I do my best to take into account the usual cases of damage, but something new always happens. I’m looking forward to the next one – honestly. Maybe someone like Thanos will come along and make half the files in the universe disappear? At least there’s something to write about when things don’t go as planned.
In general it was very helpful for me to write everything down and to recap in rest. That’s exactly what I wanted to achieve with the blog. I hope that these thoughts will lead to better decisions in the long run (as it already started with the change from Synkron to Beyond Compare).
I am aware what will be the main criticism from third parties:
- do not use a storage pool
- do not use Bitlocker
- do not use Windows
By the time I would have built up my present experience with these technologies in another technology stack (e.g. zFS, VeraCrypt, Linux), a lot of time would pass. Since I don’t get to “play” with IT much, and since it’s also about redundancy and how to behave in case of failure, it’s more than just basic knowledge and migration. Therefore, every successful recovery is rather the proof of the opposite for me.
The use of storage pools under Windows I have generally already questioned. As an alternative, I have considered zFS (have been enthusiastic about it since I first read about it in university). Currently, however, I have come to the conclusion that I don’t know enough about Linux and that new risks are likely to arise. In the end, storage pools are also a mature technology (apart from the serious patch errors of Microsoft in the last years).
What could be more appropriate to end this article with the conclusion from Chaos Radio: “Don’t let yourself be monitored and always encrypt your backups”. And now ready for Verdächtig by Systemabsturz.
Translated with www.DeepL.com/Translator (free version)